
DIGITALIZZARE L'ARCHIVIO D'IMPRESA
Quando si pensa ad un l’archivio si immagina un luogo polveroso in cui è difficile comprenderne il valore e fruire dei contenuti se non si è degli addetti ai lavori. Nella maggioranza dei casi invece celano un bene che è possibile trasformare in un valore per l’azienda di informazioni difficilmente raggiungibile e di conseguenza poco consultabile.
Proprio l’impossibilità di raggiungere questi contenuti nascosti contrasta con le aspettative di ognuno di noi che quotidianamente porta con sé uno smartphone, quindi ha l’accesso alla rete e con essa molteplici app per il proprio lavoro, lo svago ed il tempo libero. È in dubbio che i nostri stili di vita sono cambiati, pensiamo ai social strumento essenziale di comunicazione aziendale, oppure la tematica emergente dell’IOT e alla straordinaria possibilità di collegarsi a tutto e a tutti.
È evidente da tempo che questa trasformazione sociale e tecnologica porta ad una considerazione generale sulle opportunità offerte da questa innovazione, per esempio l’informazione coi quotidiani online, i portali di commercio elettronico, la formazione, le strategie ed il marketing aziendale che a ragion veduta presidia la rete considerando i nuovi media gli strumenti principali per la comunicazione interna ed esterna.
Creare quindi una sorta di big data del passato, a partire dai documenti dell’azienda, che vada ad arricchire l’universo dei contenuti internet.
La conferma di tutto ciò è l’esplosione dei contenuti Internet, un fenomeno che arricchisce e crea moltissime opportunità ma che allo stesso tempo offusca i pochi contenuti della storia passata. Questo perché la rete è affollata di contenuti e notizie recenti che riguardano gli ultimi 25-30 anni mentre del passato emergono solo i fatti noti, importanti, quelli per cui il futuro digitale è iniziato prima.
Questo fenomeno è rappresentato dal grafico sulla tendenza dell’incremento dei contenuti in internet (fig.1), osservandolo è evidente che la quantità di informazioni relative al passato ha un incremento è lineare con una bassa tendenza di crescita fino agli anni 2000, da qui in poi la curva diventa esponenziale. Questo è dovuto al fatto che i dati nativi digitali sono immediatamente disponibili e che strumenti come gli smartphone ed il cloud semplificano l’accesso a questi dati.
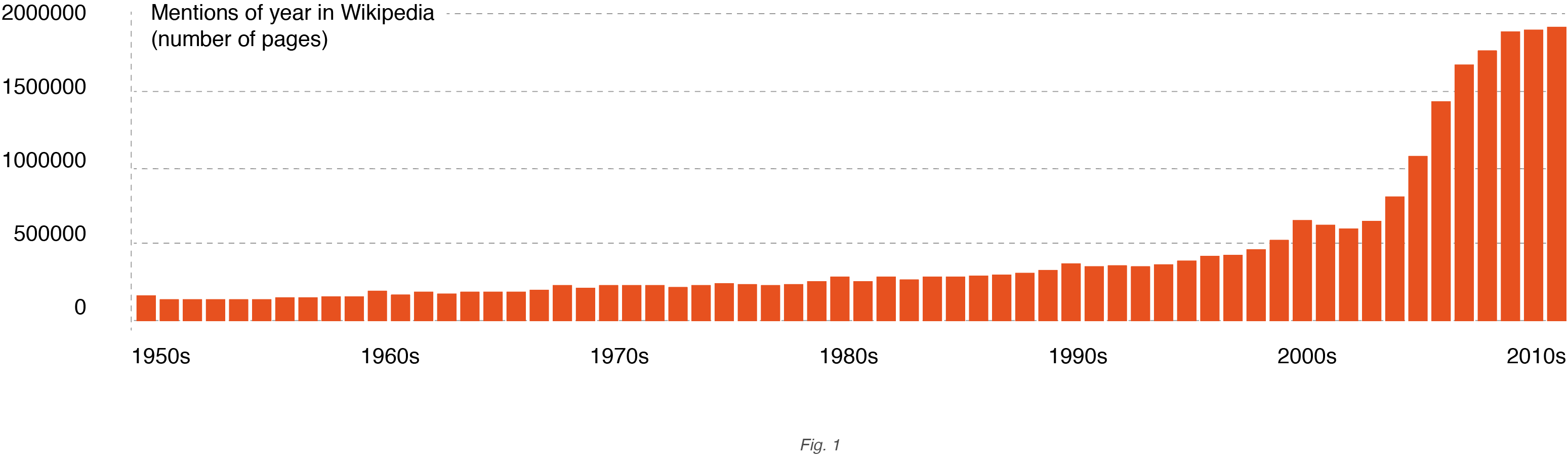
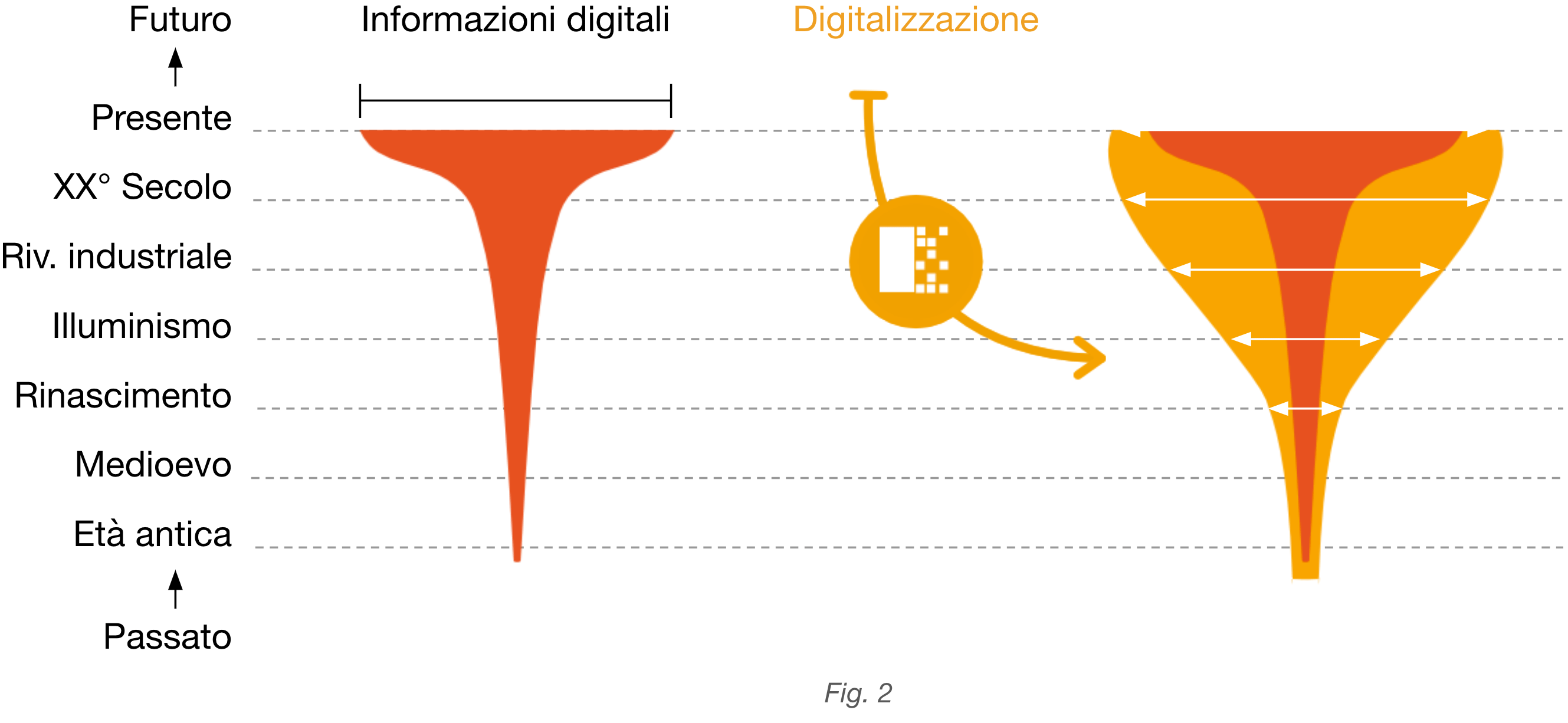
Come è possibile quindi far sì che anche il passato sia degnamente rappresentato? Nel grafico in figura 2, detto information Mushroom, viene simulato l’effetto della digitalizzazione dei contenuti “nascosti” negli archivi. Infatti si può notare nella parte sinistra che il grafico di prima (fig. 1) è stato ribaltato e specchiato per dare l’idea di questo fungo dal gambo stretto e dalla testa molto larga. A destra invece viene proposta una nuova forma a calice che rende la base più larga per effetto della digitalizzazione dei documenti passati.